

Veel organisaties beschikken over beperkt geteste en gedocumenteerde technische continuïteitsvoorzieningen voor onderdelen van hun services en hopen op het beste. Tegen die achtergrond wordt een alternatieve werkwijze voor disaster recovery planning beschreven, de Runbook First werkwijze. Deze werkwijze past bij het gemiddelde business continuity management (bcm)-level van veel organisaties en kan risico’s van grote calamiteiten op korte termijn aanzienlijk beperken.
Het vakgebied van business continuity management staat nog relatief aan het begin van zijn ontwikkeling. Sinds ongeveer twintig jaar wordt business continuity management als een afzonderlijk vakgebied ontwikkeld. Dat er in die twintig jaar veel minder progressie is gemaakt dan mogelijk is, heeft alles te maken met het feit dat de economie sinds 2007 van de ene crisis naar de andere is gegaan.
Business continuity management is een onderwerp dat in de crisis gemakkelijk door het management van organisaties op een laag pitje is gezet. Veel bcm-projecten zijn stopgezet. Veel business continuity managers hebben in de afgelopen jaren te horen gekregen dat hun functie min of meer is opgeheven. En organisaties zijn op grote schaal aan het reorganiseren geslagen: zie dat als een vorm van bcm in de eerste lijn, maar weet dan ook dat de tweede lijns continuïteitsvoorzieningen voor de nieuwe eerste lijn gemakshalve in de reorganisaties vaak buiten beschouwing worden gelaten.
De actuele situatie is dat veel organisaties beschikken over beperkt geteste en gedocumenteerde technische continuïteitsvoorzieningen voor onderdelen van hun services en hopen op het beste.
Tegen de achtergrond van die situatie in het vakgebied wordt in dit artikel een alternatieve werkwijze voor disaster recovery planning beschreven, de Runbook First werkwijze. Deze werkwijze past bij het gemiddelde bcm-maturity level van veel organisaties en kan risico’s van grote calamiteiten op korte termijn aanzienlijk beperken.
Reguliere werkwijze
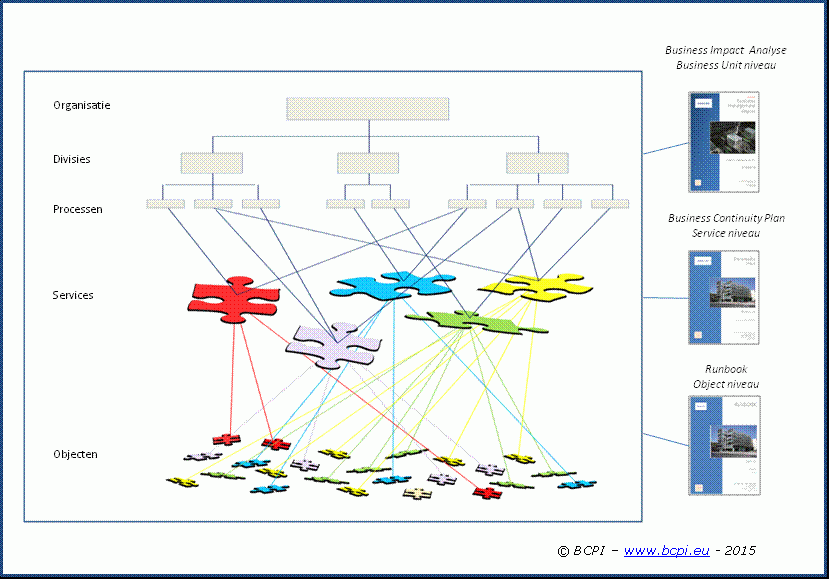
De belangrijkste deelprocessen binnen de reguliere werkwijze voor business continuity management zijn: business impact analyse, business continuity planning en disaster recovery planning. De samenhang van deze deelprocessen wordt in nevenstaande figuur schematisch weergegeven.
Risico analyse en test zijn uiteraard ook belangrijk om het juiste beeld te krijgen van de status van risicopreventie en van de effectiviteit van plannen en maatregelen. Deze processen worden in het kader van dit artikel nu niet verder uitgediept.
Business impact analyse is er op gericht om een beeld te verkrijgen van business prioriteiten en van de afhankelijkheden van business processen naar services die worden aangeboden en beheerd door ict-afdelingen, facilitaire diensten en service providers.
De gedeelde afhankelijkheid per service bepaalt de herstelprioriteit. Breed gedeelde services komen door dit afhankelijkheidsmodel automatisch hoog in de continuïteitsplanning terecht en worden daardoor normaal gesproken omgeven met de meest effectieve continuïteitsvoorzieningen.
Services zijn bijvoorbeeld: infra-services, storage-services, netwerk-services, telecom-services, thuiswerk-voorzieningen, werkplek support-services, SaaS-services, call center-services, maar kunnen ook uitbestede shared services betreffen op het gebied van logistiek of support. Voor ict-afdelingen zijn het meestal de services in de servicecatalogus die de basis vormt voor service level agreements (sla’s) met de business units.
Business continuity planning is er op gericht om binnen een paar hoofdscenario’s een vertaling te maken van business prioriteiten van services naar continuïteitsvoorzieningen op service niveau.
Een business continuity plan geeft een overall sterkte-zwakte beeld van continuïteitsvoorzieningen op service-niveau en biedt het management een feitelijke basis voor besluiten over investeringen in continuïteitsvoorzieningen op service-niveau.
Niet voor elke dreiging wordt een scenario of business continuity plan ontwikkeld. Met het oog op efficiency worden dreigingen bij voorkeur gegroepeerd naar oplossingsrichting. Per oplossingsrichting en dan meestal alleen voor de centrale locaties of functies, wordt een scenario uitgewerkt tot een business continuity plan. In het business continuity plan wordt op service-niveau aangegeven welke continuïteitsvoorzieningen voor dat scenario zijn geïmplementeerd of nog geïmplementeerd moeten worden. Wij hanteren bij BCPI drie hoofdoplossingsrichtingen: extern lang uitwijken (verlies scenario), extern kort uitwijken (evacuatie scenario) en intern oplossen
Disaster recovery planning is veel operationeler van insteek dan business continuity planning en maakt per scenario een vertaalslag van de continuïteitsvoorzieningen op service-niveau uit een business continuity plan naar herstelacties op object-niveau.
Een service wordt immers vaak uit afzonderlijke objecten in meerdere herstelacties opnieuw opgebouwd. Herstelacties voor de verschillende objecten die deel uitmaken van verschillende services tonen vaak onderlinge afhankelijkheden. Als die afhankelijkheden tijdens het herstel niet in acht worden genomen, kan dat de reden zijn dat een service technisch of functioneel niet goed opkomt.
Het product van disaster recovery planning is een gedetailleerd draaiboek of runbook waarin herstelacties voor verschillende services, die vaak door verschillende teams worden uitgevoerd, op volgorde en tijd aan de regievoerders en teams worden gepresenteerd. De noodzaak om te kunnen beschikken over operationele draaiboeken of runbooks is uiteraard groot. Indien een organisatie alleen beschikt over een continuïteitsplan op service-niveau dan is de noodzaak van improvisatie op object-niveau tijdens calamiteiten vaak groot en daarmee ook de kans op fouten. De organisatie en klanten kunnen hierdoor onnodig veel schade oplopen.
Beginnen bij het eind
Uiteraard zal het streven er op gericht zijn dat herstelacties in draaiboeken zodanig op volgorde worden gezet dat de te herstellen services opkomen volgens de prioriteiten van de daarvan afhankelijke business processen. Maar dan moeten die prioriteiten wel bekend zijn en dat betekent dat front-end business impact analyses ook beschikbaar en actueel moeten zijn. Echter, bijna alle complexe organisaties hebben moeite om front-end business impact analyses te produceren en vooral ook om die actueel te houden. Vaak ontbreekt ook de capaciteit, deskundigheid of discipline om die analyses actueel te maken of te houden.
Maar bijna alle organisaties hebben toch ook behoefte aan genoemde operationele hersteldraaiboeken. Daarvoor is een creatieve maar ook effectieve oplossing ontwikkeld: de Runbook First werkwijze.
Deze werkwijze begint bij de inventarisatie van parate kennis van alle bij herstelwerkzaamheden betrokken beheerders, intern en extern. Bij deze werkwijze geldt het devies: iedereen die het beter weet, mag (of moet) het zeggen …Alle herstelacties, aandachtspunten, reminders, potentiële fouten en oplossingen worden op grond van interviews of workshops in korte statements met eveneens korte toelichting en referenties naar detaildocumentatie in kaart gebracht. De kennis uit de hoofden van de beheerders wordt direct in herstelacties in het runbook vertaald.
Vervolgens worden herstelacties in datzelfde runbook in hoofdgroepen, subgroepen, taakgroepen en taken ingedeeld. Functionele en technische afhankelijkheden tussen groepen en tussen taken worden benoemd, evenals meest realistisch geachte doorlooptijd en het coördinerend herstelteam.
Het draaiboek of runbook is bij voorkeur voor testdoeleinden beschikbaar in absolute tijden en voor gebruik bij calamiteiten in relatieve start- en eindtijden. Een gemiddeld runbook heeft per uitwijk, migratie of terugwijk al snel tweehonderd tot driehonderd acties gekoppeld aan groepen van objecten en coördinerende teams.
Randvoorwaarde
Randvoorwaarde om deze evolutionaire werkwijze voor de disaster recovery planning toe te kunnen passen is een krachtige, relationele modelleringsfunctionaliteit, aangezien kennis in de werkwijze voortdurend evolueert en onderlinge relaties dus ook voortdurend kunnen wijzigen.
Instrumenten als Excel, Word en MS Project, die nu nog in bijna 90 procent van de organisaties wordt gebruikt voor disaster recovery planning zijn hiervoor niet geschikt. In die omgevingen is de kans op fouten in de vele vereiste hersorteringen van acties en taken te groot. Maar ook het rekenen met doorlooptijden is in die klassieke tools vaak van onvoldoende kwaliteit. Daarom is deze flexibele werkwijze eigenlijk alleen realiseerbaar met relationele modelleringsfunctionaliteit.
Die relationele modelleringsfunctionaliteit is ook om andere reden nodig. Een inherente beperking van de Runbook First werkwijze is dat herstelacties in runbooks in het begin niet direct herleidbaar zullen zijn naar de eisen, wensen en verwachtingen van de business.
Organisaties die onder toezicht staan van interne of externe auditors of certificeringsinstanties zullen worden geconfronteerd met de vraag hoe men kan aantonen dat de herstelacties in de runbooks in lijn zijn met die eisen, wensen en verwachtingen van de business. Daarom is het belangrijk dat het ook achteraf nog mogelijk moet zijn om herstelacties in runbooks te kunnen relateren aan later eventueel nog op te leveren front-end business impact analyses en business continuity plannen. Ook hier kan een relationele planningsomgeving ondersteuning bieden.
En altijd komt dan de vraag of het configuratie management systeem hiervoor kan worden gebruikt.
Het antwoord is simpelweg: ‘Nee’. Configuratie management systemen leveren wel basisgegevens maar missen de bcm en disaster recovery planning-functies. Het is als een lamp ophangen met een zaag: een zaag is ook een tool, maar niet het juiste voor dat doel. Les één voor de vakman luidt: ‘zorg altijd voor het juiste gereedschap voor de klus’.
Conclusie
Organisaties die zichzelf herkennen in de hier beschreven situatie doen er goed aan om de hogere kosten van relationele planningsomgevingen af te wegen tegen de grote voordelen van het snel kunnen beschikken over runbooks voor risicoreductie op korte termijn in verschillende scenario’s en tegen de voordelen van behoud van zicht op goedkeuring van auditors of certificerende instanties op de langere termijn.
Organisaties die streven naar kwaliteit komen dan al snel tot de conclusie dat Word, Excel en Project op termijn eerder een probleem dan een oplossing zullen blijken te zijn.





Ik heb professioneel wel iets met dit soort onderwerpen. Ik zie maar zeer weinig IT professionals echt nadenken hier over. De klanten van de IT professionals faseren duurbetaalde consultancy posten uit. Hardstikke terecht heb ik altijd geroepen.
Ik heb altijd de stelling gehanteerd dat DR niets anders moet zijn dan bestaande componenten oppakken, naar elders verplaatsen, up en running brengen. Dat vergt niets meer dan een regelmatig te oefenen (deel)scenario waar je bijna blind een proces over moet kunnen schrijven.
Uiteraard kun je dat zo ingewikkeld maken als je wilt natuurlijk maar als ik zie wat een gaten er sinds een aantal jaren er kwalitatief alleen al aan het ontstaan zijn op standaard IT taken. Dan kun je gewoon wachten op outages.
Disaster recovery dient gewoon een standaard te zijn die voor elke organisatie uiteraard een ander kleurtje kan hebben maar die moeiteloos gewoon kan worden neergepend. En dat neerpennen heeft alleen maar waarde als die routine dan ook regelmatig door leden van de organisatie gewoon word getoetst.
Je hebt het dan over de investering van een klein beetje apparatuur en wat manuren om te zien of het DR proces de lading nog wel dekt. En die investering moet je dan maar afwegen wanneer een afdeling van 50 FTE of meer plots op een middag om half twee naar huis kan vanwege een calamiteit.
Hrs Outage x FTE x Hourrate = LoP.